第二阶段
协议理解¶
实验的第二阶段是针对个人的真机测试。在这一步,你需要实现一个 RIPng 协议的路由器。你需要首先阅读 RFC 2080,并能回答下面的几个问题:
- 数据格式是怎么样的?
- UDP 端口号是?
- IPv6 源地址是?目的地址是?
- 接收到其他路由器的 RIPng 分组时,按照什么逻辑更新自己的路由表?
- 如何表示路径无穷大?如何区分路径是因为不可达还是毒性反转产生的无穷大?
- 如何实现水平分割(Split Horizon)?如何实现毒性反转(Split Horizon with Poisoned Reverse)?这两个是什么关系?
接着,阅读 RFC 4443,回答以下问题:
- PING 命令是如何通过 ICMPv6 协议实现的?为了支持 PING,需要主机响应什么类型的 ICMPv6 分组?
- ICMPv6 Echo Request 和 ICMPv6 Echo Reply 是如何对应起来的?
- 路由器在什么时候会发送 Time Exceeded 和 Destination Unreachable 类型的消息?发送的 ICMPv6 分组中,IPv6 源地址,目的地址,Hop Limit,ICMPv6 的 Payload 分别是什么?
教学目的:
- 实验的第二阶段是在第一阶段的基础上,实现一个支持 RIPng 协议的 IPv6 路由器。这一阶段的目的是,让同学理解路由器的功能和具体的实现流程。
- 让同学理解我们通常采用的 ping 工具是如何发现网络中的问题的,当出现问题的时候,这个问题是由哪个路由器报告、并且报告什么错误。那么,以后当我们用 ping 来检查网络的时候,看到错误信息,我们就可以推断出网络的问题,并且在哪里出现了问题。
- 让同学学习和尝试使用 Wireshark 来调试一个模拟的网络环境,之后,可以把同样的调试流程用在真实的网络环境上,比如宿舍的网络、实验室的网络和家里的网络。作为学习完网络原理、做完路由器实验的你,以后遇到同学或者家里人上不了网的问题的时候,就可以挺身而出,尝试定位和解决问题。这时候,你就不怕别人说:“你不是学计算机的吗,难道还不会修网络?”的问题。
- 同学可以熟悉 Linux 下的命令行操作和代码管理,这对以后做科研是很有帮助的。
工作流程¶
可以回答以上几个问题以后,结合仓库中 Homework/router/main.cpp 尝试理解下面的路由的工作流程:
- 初始化路由表,加入直连路由
- 进入路由器主循环
- 如果距离上一次发送已经超过了 5 秒,就发送完整的路由表到所有的接口
- 接收 IPv6 分组,如果没有收到就跳到第 2 步
- 检查 IPv6 分组的完整性和正确性
- 判断 IPv6 分组需要转发还是进入 RIPng/ICMPv6 协议处理
- 如果是 RIPng 分组,如果是 Request,就构造对应的 Response;如果是 Response,按照条目更新路由表
- 如果是 ICMPv6 分组,如果是 Echo Request,就回复 Echo Reply
- 如果这个分组要转发,判断 Hop Limit,如果小于或等于 1,就回复 ICMP Time Exceeded
- 如果 Hop Limit 正常,查询路由表,如果找到了,就转发给下一跳
- 如果不在路由表中,就回复 ICMP Destination Unreachable
- 跳到第 2 步,进入下一次循环处理
也可以见下面的流程图:

理解上面的工作流程后,尝试回答以下的问题:
- 为什么要区分转发逻辑/RIPng/ICMPv6 逻辑?它们用途分别是什么?
- 上面的步骤中,哪些步骤是性能瓶颈?
当你可以回答上面的问题的时候,就可以开始代码编写了。
功能要求¶
由于 RIPng/ICMPv6 协议完整实现比较复杂,我们只需要实现其中的一部分。必须实现的有:
- 转发功能,支持直连路由和间接路由,包括 Hop Limit 减一,查表并向正确的 interface 发送出去。
- 周期性地向所有端口发送 RIPng Response(周期为 5s,而不是 RFC 2080 Section 2.3 Timers 要求的 30s),目标地址为 RIPng 的组播地址。
- 对收到的 RIPng Request 生成 RIPng Response 进行回复,目标地址为 RIPng Request 的源地址。
- 实现水平分割(split horizon)和毒性反转(reverse poisoning)。
- 收到 RIPng Response 时,对路由表进行维护,处理 RIPng 中
metric=16的情况。 - 对 ICMPv6 Echo Request 进行 ICMPv6 Echo Reply 的回复,见 RFC 4443 Echo Reply Message。
- 在接受到 IPv6 packet,按照目的地址在路由表中查找不到路由的时候,回复 ICMPv6 Destination Unreachable (No route to destination),见 RFC 4443 Section 3.1 Destination Unreachable Message。
- 在 Hop Limit 减为 0 时,回复 ICMPv6 Time Exceeded (Hop limit exceeded in transit),见 RFC 4443 Section 3.3 Time Exceeded Message。
- 在发送的 RIPng Response 大小超过 MTU 时进行拆分。
可选实现的有(不加分,但对调试有帮助):
- 定期或者在更新的时候向 stdout/stderr 打印最新的 RIP 路由表。
- 在路由表出现更新的时候立即发送 RIPng Response(完整或者增量),可以加快路由表的收敛速度。
- 路由的超时(Timeout)和垃圾回收(Garbage Collection)定时器。
- 程序启动时向所有 interface 发送 RIPng Request。
不需要实现的有:
- NDP 的处理,已经在 HAL 中实现。
- interface 状态的跟踪(UP/DOWN 切换)。
HONOR CODE
在 router 目录中,有一个 HONOR-CODE.md 文件,你需要在这个文件中以 Markdown 格式记录你完成这个作业时参考网上的文章或者代码、与同学的交流情况。
网络拓扑¶
CIDR 表示方法
下面多次用到了 CIDR 的表示方法,格式是 ipv6_addr/len ,可能表示以下两种意义之一:
- 地址是 ipv6_addr,并且最高 len 位和 ipv6_addr 相同的 IPv6 地址都在同一个子网中,常见于对于一个网口的 IP 地址的描述。如
fd00::a:b/112表示fd00::a:b的地址,同一个子网的地址只有最后 16 位可以不同。 - 描述一个地址段,此时 ipv6_addr 除了最高 len 位都为零,表示一个 IP 地址范围,常见于路由表。如
fd00::a:b/112表示从fd00::a:0到fd00::a:ffff的地址范围。
在 TANLabs 提交后,会在实验室的实验网络下进行真机评测。你的软件会运行在树莓派上,和我们提供的机器组成如下的拓扑:

这一阶段,PC1、R1、R3、PC2 都由 TANLabs 自动配置和提供,两台路由器上均运行 BIRD 作为标准的路由软件实现。你代码所运行在的树莓派处于 R2 的位置。其中 R2 实际用到的只有两个口,剩余两个口按顺序配置为 fd00::8:1/112 和 fd00::9:1/112 (见 Router-Lab/Homework/router/main.cpp 代码中 ROUTER_R2 部分)。初始情况下,R1 和 R3 先不启动 RIP 协议处理程序,这些机器的系统路由表如下:
PC1:
default via fd00::1:1 dev pc1r1
fd00::1:0/112 dev pc1r1 scope link
R1:
fd00::1:0/112 dev r1pc1 scope link
fd00::3:0/112 dev r1r2 scope link
R3:
fd00::4:0/112 dev r3r2 scope link
fd00::5:0/112 dev r3pc2 scope link
PC2:
default via fd00::5:2 dev pc2r3
fd00::5:0/112 dev pc2r3 scope link
上面的每个网口名称格式都是两个机器拼接而成,如 pc1r1 代表 pc1 上通往 r1 的网口。此时,接上你的树莓派,按照图示连接两侧的 R1 和 R3 后,从 PC1 到 PC2 是不通的。接着,在 R1 和 R3 上都开启 RIPng 协议处理程序 BIRD,它们分别会在自己的 RIP 包中宣告 fd00::1:0/112 和 fd00::5:0/112 的路由。一段时间后它们的路由表(即直连路由 + RIP 收到的路由)应该变成这样:
R1:
fd00::1:0/112 dev r1pc1 scope link
fd00::3:0/112 dev r1r2 scope link
fd00::4:0/112 via fd00::3:2 dev r1r2
fd00::5:0/112 via fd00::3:2 dev r1r2
fd00::8:0/112 via fd00::3:2 dev r1r2
fd00::9:0/112 via fd00::3:2 dev r1r2
R3:
fd00::1:0/112 via fd00::4:1 dev r3r2
fd00::3:0/112 via fd00::4:1 dev r3r2
fd00::4:0/112 dev r3r2 scope link
fd00::5:0/112 dev r3pc2 scope link
fd00::8:0/112 via fd00::4:1 dev r3r2
fd00::9:0/112 via fd00::4:1 dev r3r2
在 Linux 中,上面的 via fd00:3:2 和 via fd00::4:1 在实际情况下会变成对应的 fe80 开头的 Link Local 地址。
在代码中,已经为大家设置好了一些常量,根据 ROUTER_R{1,2,3} 宏的不同定义取不同的值。在 Homework/router 目录下可以看到名为 r1 r2 r3 的目录,每个目录下都有 Makefile,分别编译出不同宏定义下的路由器。
检查内容¶
对于单人测试,TANLabs 将会自动逐项检查下列内容:
- 配置网络拓扑,在 R1 和 R3 上运行 BIRD,在 R2 上运行定义了
ROUTER_R2的路由器程序。 - 等待 RIPng 协议运行一段时间,一分钟后正式开始评测。
- 在 PC1 上
ping fd00::5:1若干次,在 PC2 上ping fd00::1:2若干次,测试 ICMP 连通性。 - 在 PC1 和 PC2 上各监听 80 端口(
sudo nc -6 -l -p 80),各自通过 nc 访问对方(nc $remote_ip 80),测试 TCP 连通性。 - 在 PC1 上
ping fd00::5:1 -t 2,应当出现Time Exceeded的 ICMPv6 响应,从 PC2 同样地运行ping fd00::1:2 -t 2,测试 HopLimit=0 时的处理。 - 导出 R1 和 R3 上 系统的路由表(运行
ip -6 route),和答案进行比对。 - 在 PC2 上运行
iperf3 -s,在 PC1 上运行iperf3 -c fd00::5:1 -O 5 -P 10,按照 Bitrate 给出分数,测试转发的效率。
在过程中,如果路由器程序崩溃退出,后续的测试项目都会失败。在实验平台上,可以看到功能和性能的原始评测结果,不公布最终折算成绩。需要注意的是,GNU netcat 不支持 IPv6,请使用 netcat-openbsd。
由于性能会计入分数,请在通过所有功能测试后,检查一下是否删除了不必要的影响性能的调试代码。
为何不在 R2 上配置 IP 地址:fd00::3:2 和 fd00::4:1
- Linux 有自己的网络栈,如果配置了这两个地址,Linux 的网络栈也会进行处理,如 ICMP 响应和(可以开启的)转发功能
- 实验中你编写的路由器会运行在 R2 上,它会进行 ICMP NDP 响应(HAL 代码内实现)和 ICMP Echo 响应(你的代码实现)和转发(你的代码实现),实际上做的和 Linux 网络栈的部分功能是一致的
- 为了保证确实是你编写的路由器在工作而不是 Linux 网络栈在工作,所以不在 R2 上配置这两个 IP 地址
- 作为保险,HAL 在 Linux 下会关闭对应 interface 的 IPv6 功能。
容易出错的地方
- Metric 计算和更新方式不正确或者不在 [1,16] 的范围内
- 没有正确处理 RIP Response,特别是 metric=16 的处理,参考 RFC 2080 Section 2.4.2 Response Messages
- 转发的时候查表 not found,一般情况是路由表出错,或者是查表算法的问题
- 更新路由表的时候,查询应该用精确匹配,但是错误地使用了最长前缀匹配
- 没有对所有发出的 RIP Response 正确地实现水平分割和毒性反转
- 字节序不正确,可以通过 Wireshark 看出
可供参考的例子
我们提供了 r1.pcap 和 r3.pcap (可点击文件名下载)这两个文件,分别是在 R1 和 R3 抓包的结果,模拟了实验的过程:
- 开启 R1 R3 上的 BIRD 和 R2 上运行的路由器实现
- 使用 ping 进行了若干次连通性测试
举个例子,从 PC1 到 PC2 进行 ping 连通性测试的网络活动(忽略 RIP):
- PC1 要 ping fd00::5:1,查询路由表得知下一跳是 fd00::1:1。
- 假如 PC1 还不知道 fd00::1:1 的 MAC 地址,则发送 NDP 请求(通过 pc1r1)询问 fd00::1:1 的 MAC 地址。
- R1 接收到 NDP 请求,回复 MAC 地址(r1pc1)给 PC1 (通过 r1pc1)。
- PC1 把 ICMPv6 包发给 R1 ,目标 MAC 地址为上面 NDP 请求里回复的 MAC 地址,即 R1 的 MAC 地址(r1pc1)。
- R1 接收到 IP 包,查询路由表得知下一跳是 fd00::3:2,假如它已经知道 fd00::3:2 的 MAC 地址。
- R1 把 IP 包外层的源 MAC 地址改为自己的 MAC 地址(r1r2),目的 MAC 地址改为 fd00::3:2 的 MAC 地址(R2 的 r2r1),发给 R2(通过 r1r2)。
- R2 接收到 IP 包,查询路由表得知下一跳是 fd00::4:2,假如它不知道 fd00::4:2 的 MAC 地址,所以丢掉这个 IP 包。
- R2 发送 NDP 请求(通过 r2r3)询问 fd00::4:2 的 MAC 地址。
- R3 接收到 NDP 请求,回复 MAC 地址(r3r2)给 R2(通过 r3r2)。
- PC1 继续 ping fd00::5:1,查询路由表得知下一跳是 fd00::1:1。
- PC1 把 ICMPv6 包发给 R1 ,目标 MAC 地址为 fd00::1:1 对应的 MAC 地址,源 MAC 地址为 fd00::1:2 对应的 MAC 地址。
- R1 查表后把 ICMPv6 包发给 R2,目标 MAC 地址为 fd00::3:2 对应的 MAC 地址,源 MAC 地址为 fd00::3:2 对应的 MAC 地址。
- R2 查表后把 ICMPv6 包发给 R3,目标 MAC 地址为 fd00::4:2 对应的 MAC 地址,源 MAC 地址为 fd00::4:1 对应的 MAC 地址。
- R3 查表后把 ICMPv6 包发给 PC2,目标 MAC 地址为 fd00::5:1 对应的 MAC 地址,源 MAC 地址为 fd00::5:2 对应的 MAC 地址。
- PC2 收到后响应,查表得知下一跳是 fd00::5:2。
- PC2 把 ICMPv6 包发给 R3,目标 MAC 地址为 fd00::5:2 对应的 MAC 地址,源 MAC 地址为 fd00::5:2 对应的 MAC 地址。
- R3 把 ICMPv6 包发给 R2,目标 MAC 地址为 fd00::4:1 对应的 MAC 地址,源 MAC 地址为 fd00::4:2 对应的 MAC 地址。
- R2 把 ICMPv6 包发给 R1,目标 MAC 地址为 fd00::3:1 对应的 MAC 地址,源 MAC 地址为 fd00::3:2 对应的 MAC 地址。
- R1 把 ICMPv6 包发给 PC1,目标 MAC 地址为 fd00::1:2 对应的 MAC 地址,源 MAC 地址为 fd00::1:1 对应的 MAC 地址。
- PC1 上 ping 显示成功。
在线评测的原理
实验团队部署了树莓派集群,对于一次个人的真机评测,会分配三个树莓派和两个 VLAN,分别对应 PC1/R1、R2 和 R3/PC2,两个 VLAN 分别对应 R1-R2 和 R2-R3,使用 veth 连接 PC1-R1 和 R3-PC2。 接着,在 R1 和 R3 对应的树莓派上进行各种配置,包括 netns、veth、forwarding 和 ethtool(关闭 generic-receive-offload) 的设置。在 R1 和 R3 上运行 BIRD,在 R2 上下载静态编译好的路由器程序,在容器里运行。接着,就按照上面所述的测试命令一条一条进行。
特别地,为了安全,程序运行在单独的 chroot 和 user 中,并且限制了 capability。同时为了保证性能的稳定性,把进程绑定到了一个 CPU 核上。另外,为了提升性能,我们把 CPU Scaling Governor 设为 performance,让树莓派在不打开超频的条件下在最大主频下运行。
本地测试¶
本地测试主要分为两个部分:首先,搭建网络拓扑,将网络中各个设备连接好;其次,在各个设备上,运行相应的软件(比如 R2 运行自己编写的路由器,R1 R3 运行标准的路由器实现),并配置好网络(比如 IP 地址,路由等等)。具体过程见下。
拓扑搭建¶
为了方便路由器的调试,我们给大家提供树莓派,用来自己搭建网络拓扑,在上面运行自己的程序并且调试。自己测试的时候,有两种办法:
- netns 或虚拟机:可以在一个设备里模拟完整的网络拓扑,好处是只需要一个设备,坏处是配置起来比较麻烦,而且有一些细节上和实际设备不一样,特别是 ethtool 相关的一些设置。
- 多设备联调:可以找你的队友或者舍友一起合作搭建一个由树莓派和笔记本连起来的调试网络。
虚拟组网¶
为了方便测试,你可以在一台计算机上模拟评测环境的网络拓扑,并相应在模拟出的五台 “主机” 中运行不同的程序(如 BIRD / 你实现的路由器软件 / ping 等客户端工具)。这对于你的调试将有很大的帮助。我们建议你采用下列的两种方式:
- 使用虚拟机安装多个不同的操作系统,并将它们的网络按照需要的拓扑连接。这一方法思路简单,并且可以做到与真实多机环境完全相同,但可能消耗较多的资源。
- 使用 Linux 提供的 network namespace 功能,在同一个系统上创建多个相互隔离的网络环境,并使用 veth (每对 veth 有两个接口,可以处在不同的 namespace 中,可以理解为一条虚拟的网线)将它们恰当地连接起来。这一方法资源占用少,但是对 Linux 使用经验和网络配置知识有较高的需求。如果你使用的操作系统不是 Linux,可以开一个 Linux 虚拟机进行这些操作。
netns 使用方法¶
针对 netns ,我们在下面提供了一些简单的指导:
和 network namespace 相关的操作的命令是 ip netns。例如我们想要创建两个 namespace 并让其能够互相通信:
ip netns add net0 # 创建名为 "net0" 的 namespace
ip netns add net1
ip link add veth-net0 type veth peer name veth-net1 # 创建一对相互连接的 veth pair
ip link set veth-net0 netns net0 # 将 veth 一侧加入到一个 namespace 中
ip link set veth-net1 netns net1 # 配置 veth 另一侧
ip netns exec net0 ip link set veth-net0 up
ip netns exec net0 ip addr add 10.1.1.1/24 dev veth-net0 # 给 veth 一侧配上 ip 地址
ip netns exec net1 ip link set veth-net1 up
ip netns exec net1 ip addr add 10.1.1.2/24 dev veth-net1
上面的命令配置了如下的虚拟网络:
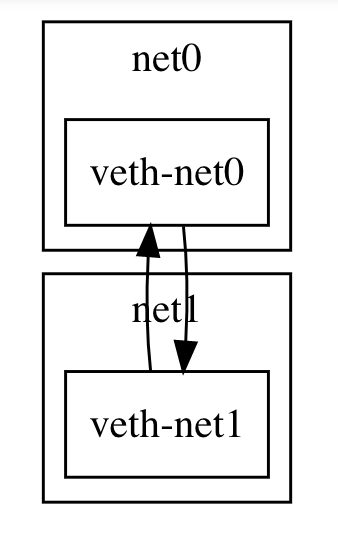
配置完成后你可以运行 ip netns exec net0 ping 10.1.1.2 来测试在 net0 上是否能够 ping 到 net1。
你还可以运行 ip netns exec net0 [command] 来执行任何你想在特定 namespace 下执行的命令,也可以运行 ip netns exec net0 bash 打开一个网络环境为 net0 的 bash。
上面的 all 可以替换为 interface 的名字。在用这种方法的时候需要小心 Linux 自带的转发和你编写的转发的冲突,在 R2 上不要用 ip a 命令配置 IP 地址,也不要打开 Linux 自带的转发功能。
想知道当前在哪个 netns 的话,可以执行 ip netns identify 命令。可以参考 FAQ 里面的方法把 netns 加入到 shell 的 prompt 中,这样会方便自己的调试。
netns 环境和真实环境的不同
由于 netns 是 Linux 里面隔离网络的一种技术,它会默认开启一些优化,比如跳过 checksum 的计算等等。所以,如果在里面直接运行你编写的路由器,很可能会把 checksum 错误的包转发出去,然后 Linux 在校验 checksum 的时候发现它是错的,而且是软件发出来的,它会选择丢弃,可能出现 TCP 连接失败的问题,详见 FAQ 中的相关讨论。
有兴趣的同学也可以尝试一下 mininet 工具来搭建基于 netns 的虚拟网络。
树莓派组网¶
树莓派的 USB 网卡按照插拔的顺序,会在 eth1-4 开始分配,在实验的拓扑里,我们建议大家改成 本机设备对端设备 的名字格式,可以通过 ip link set $old_name name $new_name 修改名字,这样方便记忆和配置。每次插拔可能都需要重新修改,可以通过常见的工具来判断是否连接到了正确的设备上。
在 Setup/rpi 目录下存放了可供参考的在树莓派的 R1 和 R3 上配置的脚本,还有恢复它的改动的脚本,注意它采用了树莓派中管理网络的 dhcpcd 进行地址的配置,所以可能不适用于树莓派以外的环境。 如果运行过配置脚本,如果要恢复环境,运行恢复脚本 Setup/restore.sh 即可,也可以手动删除 /etc/dhcpcd.conf 最后的几行内容然后用 sudo systemctl restart dhcpcd 来重启 dhcpcd。简单起见,它采用了 netns 来模拟 PC1 和 PC2,这样只需要两个树莓派就可以进行调试。
软件配置¶
我们实现的路由器实际上包括两部分功能:IPv6 分组转发和路由协议。在第二阶段中,自己写的路由器运行在 R2 上,而 R1 R3 都需要运行标准的路由器。那么,在 Linux 环境中,为了实现路由器的功能,需要下面两个部分:分组转发和路由协议。
分组转发¶
为了打开 Linux 的转发功能(例如 R1 和 R3),需要用 root 身份运行下面的命令(重启后失效):
# enable forwarding for all interfaces
echo 1 > /proc/sys/net/ipv4/conf/all/forwarding
如果你在 netns 中用 Linux 自带的功能做转发需要运行如下命令:
# enable forwarding for all interfaces in netns R1
ip netns exec R1 sh -c "echo 1 > /proc/sys/net/ipv4/conf/all/forwarding"
路由协议¶
为了实现路由协议,需要运行 BIRD。我们提供一个 BIRD(BIRD Internet Routing Daemon,安装方法 apt install bird)的参考配置,以 Debian 为例,如下修改文件 /etc/bird.conf 即可。
需要注意的是,BIRD v1.6 中,为了 IPv6 版本的 BIRD 叫做 bird6,而 IPv4 版本的 BIRD 叫做 bird;在 BIRD v2.0 中,两个版本合并了,因此都是 bird。
BIRD v2.0 配置¶
# log "bird.log" all; # 可以将 log 输出到文件中
# debug protocols all; # 如果要更详细的信息,可以打开这个
router id 网口IP地址; # 随便写一个,保证唯一性即可
protocol device {
}
protocol kernel {
# 表示 BIRD 会把系统的路由表通过 RIP 发出去,也会把收到的 RIP 信息写入系统路由表
# 你可以用 `ip route` 命令查看系统的路由表
# 退出 BIRD 后从系统中删除路由
persist no;
# 从系统学习路由
learn;
ipv6 {
# 导出路由到系统,可以用 `ip r` 看到
# 也可以用 `export none` 表示不导出,用 birdc show route 查看路由
export all;
};
}
protocol static {
ipv6 { };
route a:b:c:d::/64 via "网口名称"; # 可以手动添加一个静态路由方便调试,只有在这个网口存在并且为 UP 时才生效
}
protocol direct {
ipv6;
# 把网口上的直连路由导入到路由协议中
interface "网口名称";
}
protocol rip ng {
ipv6 {
import all;
export all;
};
debug all;
interface "网口名称" { # 网口名称必须存在,否则 BIRD 会直接退出
update time 5; # 5秒一次更新,方便调试
};
}
BIRD v1.6 配置¶
# log "bird.log" all; # 可以将 log 输出到文件中
# debug protocols all; # 如果要更详细的信息,可以打开这个
router id 网口IP地址; # 随便写一个,保证唯一性即可
protocol device {
}
protocol kernel {
# 表示 BIRD 会把系统的路由表通过 RIP 发出去,也会把收到的 RIP 信息写入系统路由表
# 你可以用 `ip route` 命令查看系统的路由表
# 退出 BIRD 后从系统中删除路由
persist off;
# 从系统学习路由
learn;
# 导出路由到系统,可以用 `ip r` 看到
# 也可以用 `export none` 表示不导出,用 birdc show route 查看路由
export all;
}
protocol static {
route a:b:c:d::/64 via "网口名称"; # 可以手动添加一个静态路由方便调试,只有在这个网口存在并且为 UP 时才生效
}
protocol direct {
# 把网口上的直连路由导入到路由协议中
interface "网口名称";
}
protocol rip {
import all;
export all;
debug all;
interface "网口名称" { # 网口名称必须存在,否则 BIRD 会直接退出
update time 5; # 5秒一次更新,方便调试
};
}
配置使用¶
这里的网口名字对应你连接到路由器的网口,也要配置一个固定的 IP 地址,需要和路由器对应网口的 IP 在同一个网段内。配置固定 IP 地址的命令格式为 ip a add IP地址/前缀长度 dev 网口名称,你可以用 ip a 命令看到所有网口的信息。
以下以 BIRD v1.6 为例:启动服务(如 systemctl start bird6)后,你就可以开始抓包,同时查看 bird 打出的信息(journalctl -f -u bird6),这对调试你的路由器实现很有帮助。
你也可以直接运行 BIRD(bird6 -c /etc/bird.conf),可在命令选项中加上 -d 把程序放到前台,方便直接退出进程。若想同时开多个 BIRD,则需要给每个进程指定单独的 PID 文件和 socket,如 bird6 -d -c bird1.conf -P bird1.pid -s bird1.socket 。
在安装 BIRD(sudo apt install bird)之后,它默认是已经启动并且开机自启动。如果要启动 BIRD,运行 sudo systemctl start bird6;停止 BIRD: sudo systemctl stop bird6;重启 BIRD:sudo systemctl restart bird6;打开开机自启动:sudo systemctl enable bird6;关闭开机自启动:sudo systemctl disable bird6。
配合 BIRD 使用的还有它的客户端程序 birdc6,它可以连接到 BIRD 服务并且控制它的行为。默认情况下 birdc 会连接系统服务(systemctl 启动)的 BIRD,如果启动 BIRD 时采用了 -s 参数,那么 birdc 也要指定同样的 socket 路径。
对于一条静态路由(如 route a:b:c:d::/64 via "abcd"),它只有在 abcd 处于 UP 状态时才会生效,如果你只是想让 BIRD 向外宣告这一条路由,可以用 lo(本地环回)代替 abcd 并且运行 ip l set lo up。你可以用 birdc6 show route 来确认这件事情。
快捷脚本¶
实验仓库中,在 Setup/netns 目录下提供了在 netns 环境下的 BIRD 配置,你可以参考里面的进行配置。
你还可以在作业仓库的 Setup/netns 目录下找到通过 netns 模拟评测环境的脚本(个人评测 setup-netns.sh,组队评测 setup-netns-group.sh),你需要先尝试阅读并理解里面的脚本代码, 在理解脚本代码 后再执行并在里面运行自己的程序。
第二阶段实验是怎么设计出来的?
第二阶段实验首先是确定了一个网络拓扑,其次才是在网络中测试路由器的功能。如果只有两个路由器,一个运行标准实现,一个运行同学的实现,那就无法判断同学实现的路由器是否正确地把学习到的路由再发送出去,因此最少需要三个路由器。此外,为了模拟终端用户,也是在 R1 R3 的两侧分别设置了两个客户端 PC1 和 PC2,它们对网络中的路由器如何配置是不关心的,它们只知道默认路由,并且可以通过默认路由来访问对方,这也模拟了我们最常见的网络访问形式。因此,网络拓扑设计成了 PC1-R1-R2-R3-PC2 这样的形式。实际上可以设计更复杂的网络拓扑,但是为了减少同学们理解的负担,就简化成一条线的形式。
对于如何测试路由器的功能,也是采用了网络中常见的手段:ping,traceroute,iperf 等等。ping 就是考察了路由表的正确性和转发功能;traceroute 在实验中通过设置不同 hlim 来实现,考察了当 hlim 降为 0 时的处理;iperf 则是让同学对网络性能有一个概念,并且知道代码中哪些部分对性能影响大,哪些部分影响不大。
这一阶段还希望大家理解和掌握网络模拟和调试的一些方法和工具:wireshark 和 netns。首先是希望同学掌握网络中的调试方法,之后在遇到网络不通的时候,不再是毫无方向地尝试各种方法,而是按照一定的思路,查看网络各处的状态,排除出问题所在。其次是希望同学接触一些比较先进的网络技术,比如 netns,可以在 linux 环境中模拟各种各样的网络,也可以让大家了解常见的容器技术是如何实现网络隔离的。如果同学不感兴趣具体原理,也可以直接用提供好的脚本来搭建基于 netns 的网络环境。